學習多執行緒最好的方式就是直接實作一個小專案,在這邊我參考台大資工系統程式設計課的其中一個作業:實作一個多執行緒的方陣乘法器 (Programming HW4 - Matrix Multiplication Machine - HackMD),有興趣可以直接看這個spec挑戰看看。
我主要是以這份作業作為發想,但是對一些細節做簡化,只留下我認為重要的觀念,我也會盡量讓我的文章是self-contained的,所以可以直接看我的文章就可以了!
最終程式碼:Cpp-Projects/thread-pool/thread-pool.c at main · loijilai/Cpp-Projects (github.com)
本篇目標
這篇文章的重點會放在「怎麼設計一個執行緒池的介面」給主執行緒使用,而不會講到實作的部分。
為了把重點放在實現多執行緒的控制,我對一些細節做了簡化:
- 把矩陣限定在大小為n的方陣就好
- 執行緒池的大小固定,而不會隨著工作量自己scale up
(給有點開作業連結的人)
-
原始作業的spec中,執行緒池不是每個執行緒都做一樣的事情,有一個frontend跟很多backend。 但其實frontend在做的事情給主執行緒做就好了,是不必要的設計,我猜是為了當作程式練習才做這樣設計,所以這邊我簡化讓每個執行緒池的執行緒都做一樣的事情就好,也比較符合一般的情況。
-
原始作業的spec中,每個request可能被拆成不同數量個work,但我統一都拆成n個,這部分也是可以根據個人需求微調
我們要解的問題
我們先看最簡單的矩陣乘法,是一個O(n^3)的演算法。
// O(n)
int inner_product(int n, Vector a, Vector b) {
int result = 0;
for(int i = 0; i < n; i++) {
result += a[i] * b[i];
}
return result;
}
// 計算矩陣乘法:A * B = C
int matrix_multiplication(int n, Matrix A, Matrix B, Matrix C) {
// inner_product是O(n), 執行n^2次,總共O(n^3)
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
C[i][j] = inner_product(A.row(i), B.col(j));
}
}
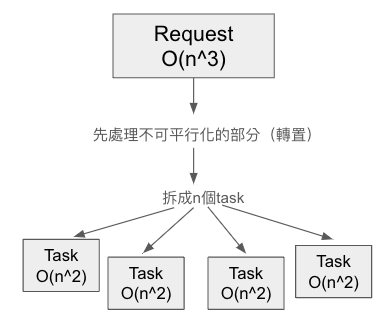
}這個任務一定要同時做嗎?當然不必,矩陣C中的每個元素結果都是相互獨立的,每個內積應該可以分開執行,所以這是一個非常適合用多執行緒的問題。但是在C語言中要表示行向量跟列向量的區別有點麻煩,所以我們先把B矩陣轉置,這樣就可以統一做列向量的內積了。
// 剛才的版本
C[i][j] = inner_product(A.row(i), B.col(j));
// 轉置後的版本
B = transpose(B)
C[i][j] = inner_product(A.row(i), B.row(j)); // 統一取.row()這是一個常見的場景:一個任務有可以平行化和不可平行化的兩個部分,也因此針對矩陣轉置的部分,我們之後要特別去處理。
至於拆分完task的顆粒度,可以拆成最小計算一個元素(就是一次內積),但這邊我是拆成計算矩陣的一個row,而一個row有n個元素,每個元素需要O(n)算內積,所以每個task是n*O(n)=O(n^2)。
這是因為如果task切的太小很沒效率,大部分時間都會花在執行緒競爭task上。
我們要提供給使用者的介面
tpool_request
對於想做方陣乘法的人,也就是主執行緒,他不想管太多,反正矩陣進得去答案出的來就好,其他都交給執行緒池處理就對了,所以主執行緒只負責送request,我們可以設計一個介面給他用:
// 主執行緒:幫我計算方陣乘法吧!
// tpool_t *tp: 執行緒池
// Matrix a, b: 要計算乘法的方陣
// Matrix c: 存放計算結果的方陣
void tpool_request(tpool_t *tp, Matrix a, Matrix b, Matrix c);tpool_synchronize
另外如果使用者要把計算結果印出來,他需要確保前面的request都已經做完計算才去取用答案,不然執行緒池還沒算完他就去取答案會出錯。
所以為了讓使用起來更方便一些,我們提供一個同步的功能讓主執行緒呼叫,使用者如果想要確保所有之前送進去的request都完成,就直接呼叫這個API就好。
// 主執行緒:把前面送進去的request都算完吧!我在這裡等到你好了再繼續
void tpool_synchronize(tpool_t *tp);tpool_init & tpool_destroy
最後我們還要設計給使用者初始化和清理執行緒池的介面,方便他管理使用的週期。
// 初始化一個用來計算n*n方陣的執行緒池,裡面有num_threads個執行緒
tpool* tpool_init(int num_threads, int n);
// 清理乾淨,我不要用了
void tpool_destroy(struct tpool *tp);全部放在一起
整體使用起來大概會像這樣:
typedef int** Matrix;
typedef int* Vector;
int main() {
int num_threads;
int matrix_size;
int num_requests;
scanf("%d", &num_threads); // 使用者決定要用幾個執行緒
scanf("%d", &matrix_size); // 使用者決定方陣的大小
scanf("%d", &num_requests); // 使用者決定有多少個request
// 初始化執行緒池
struct tpool *tp = tpool_init(num_threads, matrix_size);
if(tp == NULL) {
fprintf(stderr, "main: tpool_init failed\\n");
return -1;
}
// 讀取要計算的方陣
// a[0], b[0]是一組、a[1], b[1]是一組, ...
// c是我們存放計算結果的地方
Matrix a[num_requests], b[num_requests], c[num_requests];
for(int i = 0; i < num_requests; i++) {
a[i] = calloc(matrix_size, sizeof(Vector));
b[i] = calloc(matrix_size, sizeof(Vector));
c[i] = calloc(matrix_size, sizeof(Vector));
for(int j = 0; j < matrix_size; j++) {
a[i][j] = calloc(matrix_size, sizeof(int));
b[i][j] = calloc(matrix_size, sizeof(int));
c[i][j] = calloc(matrix_size, sizeof(int));
}
for(int j = 0; j < matrix_size; j++) {
for(int k = 0; k < matrix_size; k++) {
scanf("%d", &a[i][j][k]);
}
}
for(int j = 0; j < matrix_size; j++) {
for(int k = 0; k < matrix_size; k++) {
scanf("%d", &b[i][j][k]);
}
}
// 每一組都呼叫一次tpool_request,把結果存放到對應的c裡面
tpool_request(tp, a[i], b[i], c[i]);
}
// 確認前面的計算結果都好了我才能print結果
tpool_synchronize(tp);
// 印出計算結果
for(int i = 0; i < num_requests; i++) {
for(int j = 0; j < matrix_size; j++) {
for(int k = 0; k < matrix_size; k++) {
printf("%d ", c[i][j][k]);
}
printf("\\n");
}
}
// 把執行緒池清理乾淨
tpool_destroy(tp);
// free()掉a, b, c
// ...
return 0;
}了解了使用者會怎麼呼叫我們提供的API之後,我們要開始設計怎麼實作這個執行緒池了!