為什麼在分散式系統裡需要 Kafka
在微服務架構中,造成最大複雜度的就是服務之間的「直接依賴」。舉例來說,當使用者完成一筆訂單時,訂單服務可能需要同步呼叫庫存服務、付款服務、通知服務。如果其中任何一個服務變慢或暫時不可用,整個流程就會被卡住,甚至直接失敗。這種高度同步(synchronous)的設計,會讓系統在規模放大後變得脆弱又難以維護。
Kafka 出現的目的,正是為了解決這類問題。它讓服務之間不需要直接呼叫彼此,而是改成「發布事件」。訂單服務只要把「訂單已建立」這個事件送進 Kafka,就可以繼續往下執行,不必等待後續行為完成。至於庫存、通知或分析服務,是否要處理這個事件、什麼時候處理,則由它們自己決定。
這種設計的核心價值在於解耦。事件的發送者不需要知道有哪些接收者,也不需要關心對方是否在線或是否處理得夠快。整個系統因此從緊密同步的呼叫關係,轉變為非同步、鬆耦合的事件流。
Kafka 是怎麼組成的
Kafka 通常以叢集(cluster)的形式運作,而不是單一機器。
叢集裡最主要的角色是 broker。你可以把 broker 想成是 Kafka 的「資料節點」,所有的訊息實際上都存放在 broker 上,也由它們負責回應 producer 和 consumer 的讀寫請求。一個 Kafka 叢集通常會有多個 broker,讓資料與流量可以分散到不同機器上。
Kafka Record Structure
Kafka 的核心概念是事件(Event)。在實作層面上,事件會以一筆訊息(message/record)的形式存在於 Topic 中。
-
Key(可選)
用來決定訊息會被寫入哪個 partition。相同 key 的訊息通常會進入同一個 partition,以確保處理順序。
-
Value(Payload)
真正要傳遞的資料內容。e.g. JSON / Avro / Protobuf
-
Headers(可選,輕量的 metadata)
附加的中繼資料,例如事件類型、版本號或 trace id,不影響 partition 決策。
-
Timestamp
訊息的時間資訊,可代表事件發生時間或寫入 Kafka 的時間。
-
Offset
Kafka 在 partition 內為每則訊息分配的序號,用於 consumer 追蹤消費進度。每個 consumer 會定期 commit offset 以保留進度。
Kafka 透過 partition 解決 scalability 的問題
Kafka 中的資料會被歸類到 topic。你可以把 topic 想成是一條事件的主題,例如「訂單事件」或「使用者行為事件」。真正影響效能的關鍵,則在於 partition,一個 topic 可以被拆分成多個 partition。
注意
-
partition 是 topic 的資料分割而非複製
整個 topic 的所有訊息,會被分散存放在不同的 partition 中,把這些 partition 聯集起來,才是完整的 topic。
-
這樣的設計,讓 Kafka 能夠同時處理大量資料。不同的 partition 可以分散在不同的 broker 上,讀寫請求自然也能被分散。當流量增加時,只要增加 partition 或 broker,就能水平擴充效能,而不需要升級單一機器。
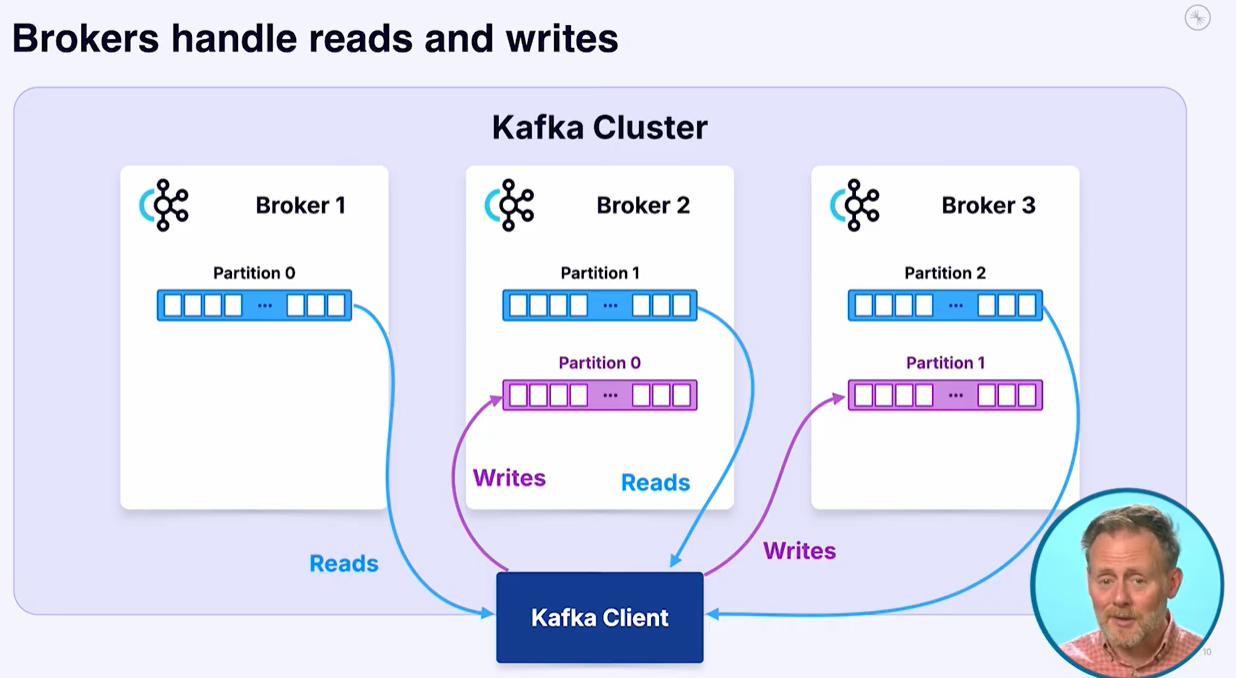
問題
但分割成多個 partition,要怎麼決定 message 該送到哪個 partition?
而且當 partition 數量很多時,同一個 topic 裡的 message 順序不就會被打亂嗎?
-
如果需要在同一個 topic 的 message 之間維持順序,producer 可以使用 key(例如訂單編號)。
Kafka 會先對 key 做 hash,再對 partition 數量取 mod,確保相同 key 的 message 會依序被寫入同一個 partition。 -
如果沒有設定 key,則預設會使用 round-robin 的方式,將 message 平均分配到各個 partition。
-
上述 partition 的選擇邏輯,都由 Kafka client library 處理。
在實際寫程式時,通常不需要自行實作或關心這些底層細節,只要透過 API 傳送 message 即可。
Kafka 透過 replication 解決 data reliability 的問題
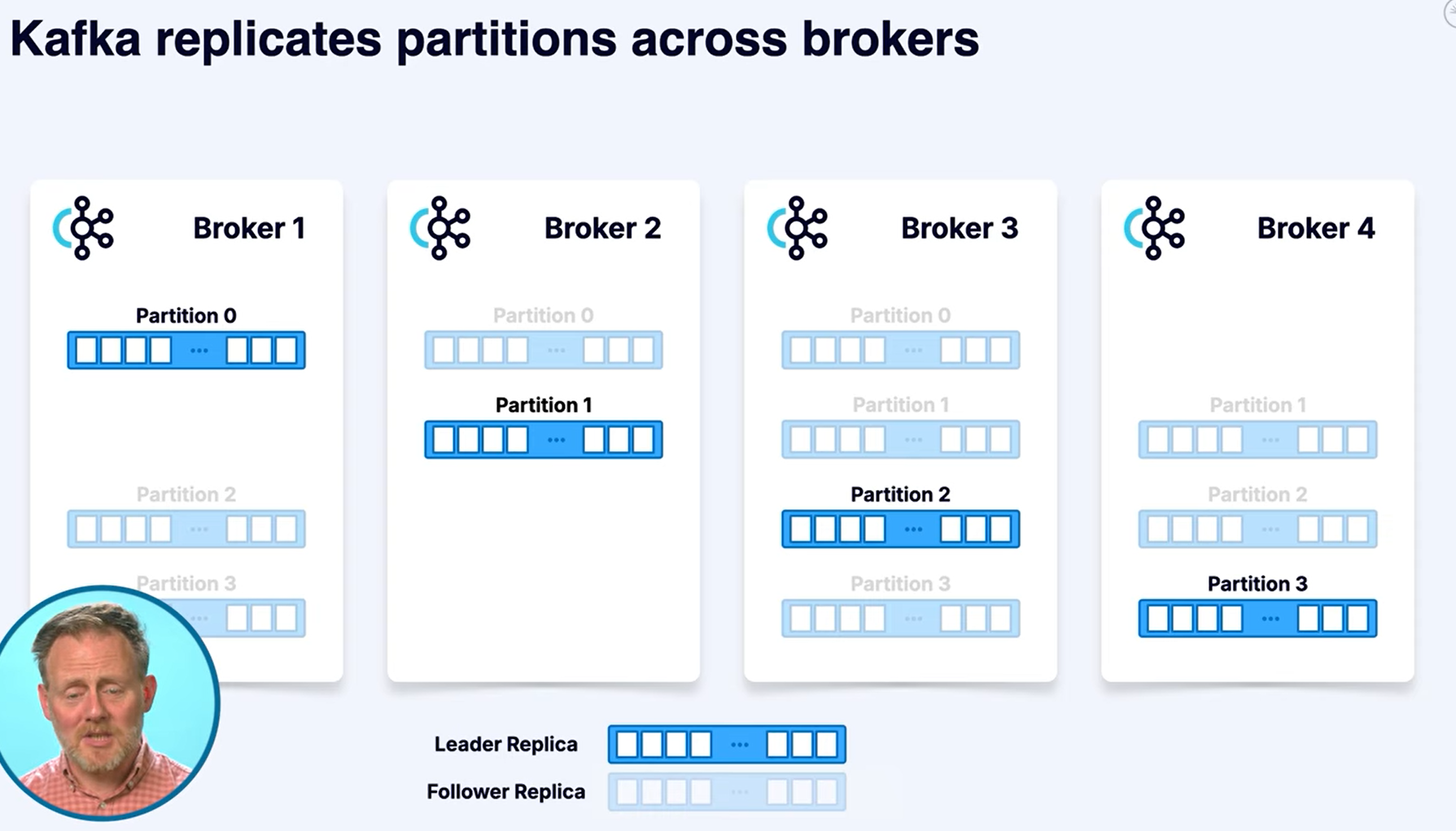
高效能之外,Kafka 也非常重視資料可靠性,這是透過 replication 機制達成的。
Replication 發生在 partition 的層級,而不是整個 topic。換句話說,每一個 partition 都可以有多個副本,分散存放在不同的 broker 上。這樣即使其中一台 broker 當機,其他 broker 上的副本仍然可以繼續提供資料。
Replication factor 用來描述「每個 partition 會有幾份副本」。如果 replication factor 是 3,代表每個 partition 會同時存在於三個不同的 broker 上。Kafka 會在這些副本中選出一個 leader,負責處理讀寫,其餘則是 follower,負責同步資料並在 leader 掛掉時接手。
這種設計讓 Kafka 在硬體故障時,不需要人工介入就能維持服務,對於需要長時間穩定運作的系統尤其重要。
用 Consumer Group 達到 consumer 的平行處理
效能瓶頸也可能發生在 consumer 端,這就是為甚麼需要 consumer group 平行處理大量的事件。
但是當有多個 consumers,要怎麼把 partition 分配給不同的 consumers ?
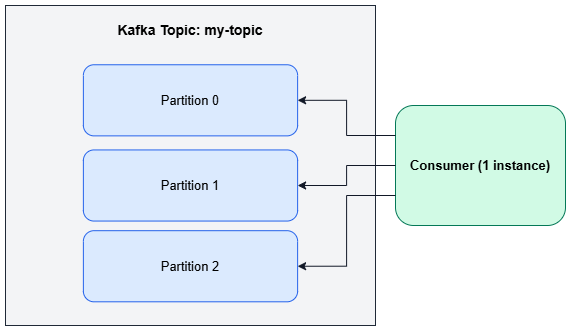 以上是尚未平行化的情形,一個 consumer 疲於處理一個 topic 中的三個 partitions。
以上是尚未平行化的情形,一個 consumer 疲於處理一個 topic 中的三個 partitions。
Consumer group 可以想成是一個「協作單位」。同一個 group 裡的多個 consumer,會一起分工處理某個 topic 的資料。
重點在於:在同一個 consumer group 中,一個 partition 在同一時間只會被一個 consumer 處理。也就是說,group 內的 consumer 不會共享同一個 partition。
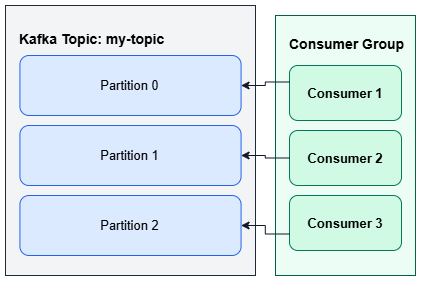
舉個實際情境來看。假設有一個 topic 叫做 my-events,裡面有 3 個 partition,而你啟動了一個 consumer group,裡面有 3 個 consumer instance。Kafka 會把這 3 個 partition 分配給這 3 個 consumer,例如每人各處理 1 個 partition。這樣同一筆訊息只會被其中一個 consumer 處理一次,不會重複。
如果你再啟動第四個 consumer,但 partition 仍然只有 3 個,那麼最多也只能有 3 個 consumer 真正做事,多出來的 consumer 只會閒置。這也是為什麼常說 consumer 的擴充能力,受限於 partition 的數量。
另一方面,如果你啟動的是另一個 consumer group(例如一個用來發送通知,一個用來做分析),那麼每個 group 都會各自完整地消費一次 topic 裡的所有訊息。這讓 Kafka 可以同時支援多種不同用途,而不需要 producer 做任何改動。
總結
Kafka 透過事件導向的設計,讓微服務之間不再直接依賴彼此,降低了同步呼叫帶來的風險。Partition 提供了效能與水平擴充的基礎,而 replication 則確保資料在故障情況下依然安全。Consumer group 的設計,讓資料既不會在同一組處理邏輯中被重複消費,又能被不同用途的系統各自完整使用。
References
Topics | Apache Kafka 101 (2025 Edition) - YouTube
Apache Kafka Partition Strategy: Optimizing Data Streaming at Scale